28 ноября 2018 года в рамках V Международного форума Финансового университета представители бизнеса и академического сообщества обсудили развитие технологий машинного обучения в финтехе и банкинге. Организатором панельной дискуссии с участием руководства ведущих российских банков стал департамент анализа данных, принятия решений и финансовых технологий Финуниверситета.
Дискуссию открыл первый вице-президент, руководитель ИТ-блока Газпромбанка, заведующий кафедрой «Банковская автоматизация и информационные технологии» Финансового университета
Дмитрий Айратович Назипов.

«Обобщенно мы знаем о человеке все. Но как эти данные нормальным образом собрать, проанализировать и, главное, монетизировать – вот что является философским камнем современной эпохи», – подчеркнул Д.А. Назипов.
По его словам, сейчас банковская система только учится работать с информацией о клиентах, полученной не от них самих, и примерно 90% пользователей готовы обменять privacy на сервис и комфорт. Грандиозный скачок в использовании больших данных должен произойти в ближайшие пять лет.
«Сочетание трех технологий – больших данных, удаленного доступа и биометрии – определит лицо не только банкинга, но и цивилизации, – заключил Д.А. Назипов, – А большие данные, которые используются торговыми сетями и в банковском ритейле, придут и в практику работы правительств и государств».

Начальник управления развития инфраструктуры анализа данных Газпромбанка Сергей Владимирович Кузнецов подчеркнул, что успешное использование больших данных требует изменения бизнес-процессов. В частности, в командах разработки и внедрения необходимо появление новых ключевых ролей – data scientist и data engineer.
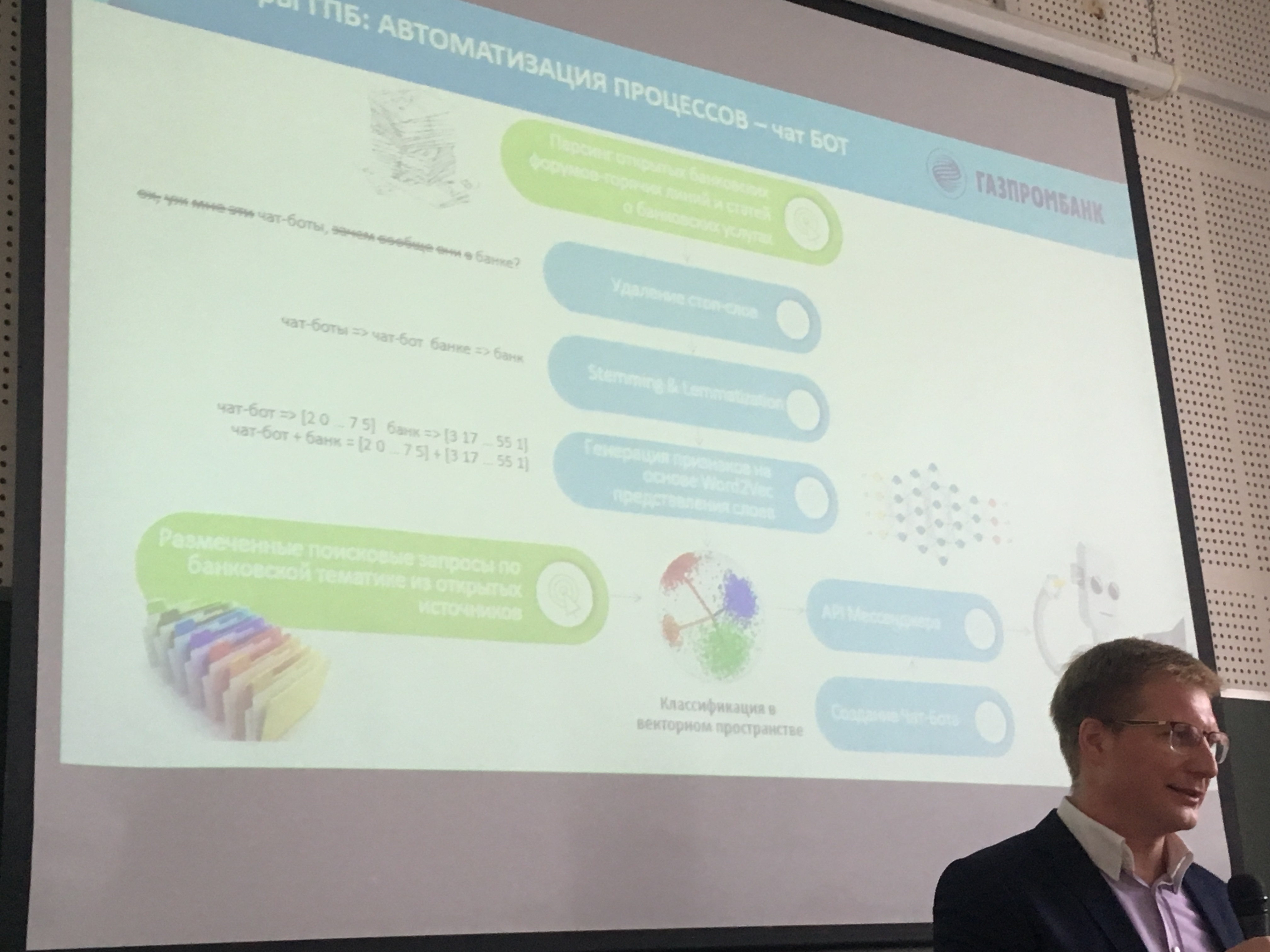
«Чтобы суметь все это сделать в организации, необходимо понимание того, что это не самый простой путь, и он требует не только установки систем», – отметил он.
По словам С.В. Кузнецова, для успешной работы с большими данными компаниям необходимо «выработать концепцию, которая позволит сделать разработку и применение моделей анализа больших данных операционным процессом», и начать «предоставлять модель как сервис для всех остальных подразделений».

В Газпромбанке уже разработана графовая платформа, использующая данные по транзакциям, активностям и социальным связям клиентов. Кроме того, созданы геоплатформа для анализа геопривязки и чат-бот для оптимизации работы колл-центра.
«Мы идем к тому, чтобы как можно меньше спрашивать у самого человека, и как можно больше данных для его обслуживания доставать из доступных источников», – закончил свое выступление С.В. Кузнецов.
Скачать презентацию Сергея Кузнецова «Данные как основа цифровой трансформации»
Руководитель департамента анализа данных, принятия решений и финансовых технологий Финуниверситета, профессор
Владимир Игоревич Соловьев рассказал о создании интеллектуальных сервисов в Финансовом университете – в частности, о системе отслеживания вовлеченности студентов в образовательный процесс. Система основана на модели машинного обучения, а для ее запуска аудитории были оснащены видеокамерами для сбора изображений лиц. Средний уровень вовлеченности в университете в прошлом семестре составил 78%.

«Главное, что мы получили, – это развитие компетенций проектной команды, потому что дальше такая система может использоваться где угодно в клиентском сервисе», – отметил В.И. Соловьев.
Еще одним проектом стало интеллектуальное прогнозирование разворотов рыночных трендов на основе данных о котировках. Практический результат исследований уже внедрен в Управляющей компании «Альфа-Капитал». Кроме того, сейчас заканчивается разработка новой версии модели, которая дает более точные прогнозы за счет использования для прогнозирования сверточных нейронных сетей.
«Сейчас – время быстрых побед. Потом будет все сложнее и сложнее строить модели, которые смогут давать прирост в качестве результата. Для этой работы потребуется много профессионалов», – заключил В.И. Соловьев.
Скачать презентацию Владимира Соловьева «Искусственный интеллект в Финансовом университете: Проектный опыт»
Начальник управления банковских процессов и технологий, вице-президент Банка ВТБ
Карл Тайстович Сумманен начал выступление с рассказа о разработке цифровой расчетной системы на блокчейне, которая сможет осуществлять переводы в режиме реального времени и использовать смарт-контракты для конверсионных операций с моментальной поставкой валюты. По его словам, сейчас в банке ведутся эксперименты с разными вариантами распределенных реестров для повышения уровня производительности, и 10 000 транзакций в секунду вполне достижимы. Говоря о машинном обучении и нейронных сетях, он отметил опасность их использования в банкинге.

«Всегда есть какие-то ситуации, которые не попали в обучающую выборку. И если на практике такая ситуация случится, и мы попросим нейронную сеть что-то сделать или предсказать – ответ может оказаться неправильным. Поэтому для задач операционного характера в банках использование нейронных сетей, на мой взгляд, немного опасно… Оправданнее использовать байесовские сети», – заявил К.Т. Сумманен.
Кроме того, К.Т. Сумманен подчеркнул и важность технологического суверенитета страны в эпоху больших данных.
Подробнее эту тему развил
Дмитрий Леонидович Гребенщиков – заместитель управляющего директора компании «Диасофт Платформа». Он рассказал о разработке платформы Diasoft Framework, которая является аналогом SAP NetWeaver и предназначена для создания бизнес-приложений. Сделаны также адаптеры для перевода данных из баз Oracle, Microsoft и др. в СУБД, которые разрабатываются на основе открытого исходного кода и поддерживаются российскими командами разработчиков. Вместе с тем, он призвал обдуманно подходить к вопросу импортозамещения в сфере разработки программного обеспечения.

«Я призываю подходить экономически обоснованно и эффективно к задаче импортозамещения ПО – его нужно проводить только там, где необходимо. Например, это оборонный сектор, какие-то стратегические национальные предприятия», – подчеркнул Д.Л. Гребенщиков.
Скачать презентацию Дмитрия Гребенщикова «Продукты и услуги компании "Диасофт Платформа"»
Заместитель заведующего кафедрой «Банковская автоматизация и информационные технологии» Финуниверситета, доцент
Сергей Вячеславович Макрушин посвятил свое выступление семантическим технологиям и их применению в бизнесе.
«После хайпа середины нулевых семантические технологии уже вышли на уровень рабочих решений, и они достаточно массово используются, хотя мы, как пользователи, этого не замечаем, – рассказал он, – Одна из прикладных технологий семантических сетей – это внедрение метаданных в веб-страницы».
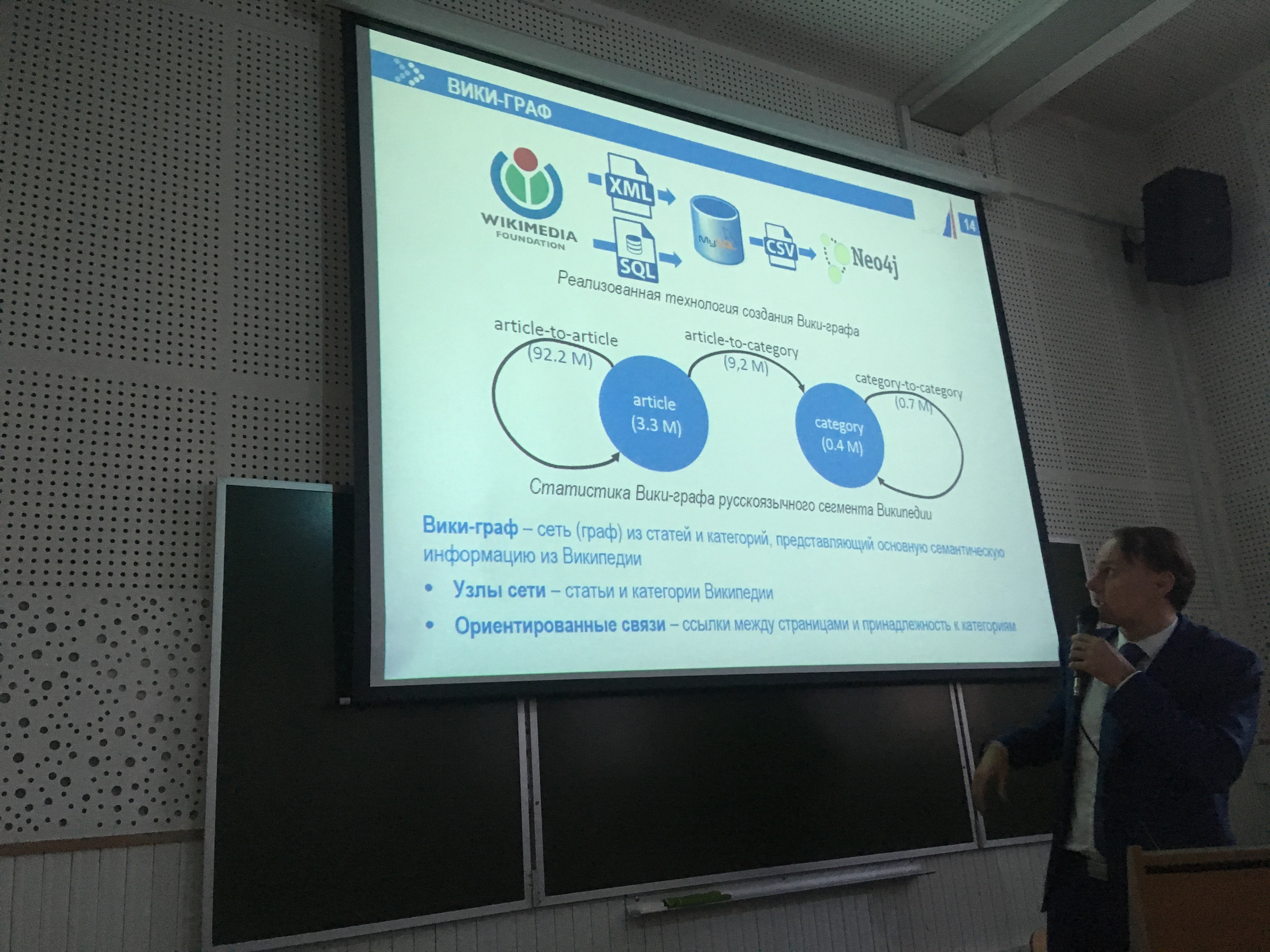
По словам С.В. Макрушина, попытки создать глобальную «семантическую паутину» (semantic web), пригодную для машинной обработки, предпринимались уже давно, однако она так и не была сделана. Вместе с тем, уже сейчас существуют большие универсальные онтологии (например, Wikidata, объединяющая 52 млн размеченных сущностей).
«Мы можем использовать уже построенные большие семантические сети для того, чтобы надстроить над ними какие-то свои корпоративные приложения», – отметил С.В. Макрушин.
Говоря о конкретном опыте, он рассказал, в частности, о создании технологии построения Вики-графа на основе данных Википедии. Вики-граф помогает построить семантический портрет документа и автоматически связать его с другими документами, что позволит решать определенные бизнес-задачи по обработке документов без участия человека или существенно повысить производительность труда операторов за счет подсказок информационной системы.
«Нет смысла бороться с ростом влияния семантических сетей на процесс взаимодействия человека с информацией. Надо включаться в процесс развития и пожинать плоды прогресса», – заключил он.
Скачать презентацию Сергея Макрушина «Семантические технологии: Новое качество обработки информации в бизнесе»
Дискуссия завершилась выступлением
Антона Алексеевича Лосева, заместителя руководителя департамента анализа данных, принятия решений и финансовых технологий Финуниверситета, который рассказал об имитационном моделировании промышленного производства с использованием когнитивной модели и итоговым созданием маркетплейса, работающего на основе смарт-контрактов.

По его словам, переход к так называемым «цифровым фабрикам» начался в 2015 году, и первопроходцем в данной области стала компания Siemens. Сейчас основные проблемы индустрии – это отсутствие прозрачности и ограниченные возможности планирования, а также конфликт интересов между участниками процесса и производством. В целях оптимизации процесса научной группой был построен прототип модели с использованием имитационного моделирования в среде AnyLogic. В дальнейшем созданное решение будет применяться для оптимизации процесса поставок деталей в рамках промышленных производств.
Скачать презентацию Антона Лосева «Модели планирования и оптимизации производства»

Четыре часа интеллектуальной работы пролетели незаметно. Каждое выступление провоцировало интересные вопросы аудитории. При этом представители бизнеса и академического сообщества говорили на одном языке, и разошлись все с новым пониманием возможностей, которые машинное обучение открывает в финтехе, банкинге и обществе.
